Dans cet article, nous verrons comment créer un petit programme d’analyse de sentiments (sentiment analysis). En effet, le programme sera chargé de récupérer les tweets liés à 2 mots-clés spécifiés au travers d’une interface graphique, en temps réel, puis attribuera à chacun de ces tweets, un score qui permettra de connaître la polarité du message ; c’est-à-dire si l’auteur du tweet a voulu exprimer un sentiment positif (la joie par exemple) ou un sentiment négatif (comme l’inquiétude).

L’analyse de sentiment fait partie d’un domaine d’étude plus large appelé NLP pour Natural Language Processing. Il s’agit de faire « comprendre » par un programme informatique les codes du langage humain. Les domaines d’application en NLP sont nombreux et l’on peut citer la reconnaissance vocale, la traduction automatique, les assistants virtuels, la détection de spam et … l’analyse de sentiments (ou opinion mining ou sentiment analysis) !
Le but de ce projet est de montrer que l’on peut rapidement prototyper une application de ce type.
Pour ce programme, nous utiliserons Python comme langage et plus précisément les modules TKinter (pour créer une interface graphique), Tweepy (pour communiquer avec Twitter), Matplotlib (pour créer des graphiques) ainsi que TextBlob (pour la partie NLP). Nous utiliserons aussi, brièvement, Pandas et Numpy, deux piliers de l’analyse de données et du calcul en Python.
Attention : Ce projet n’est pas destiné aux débutants en programmation. Si vous débutez et que vous venez de tomber sur cet article, prenez un cours de Python comme il en existe de très bien faits et gratuits sur Internet (ou consultez le mien 🙂 ).
Table des matières
Démonstration du programme
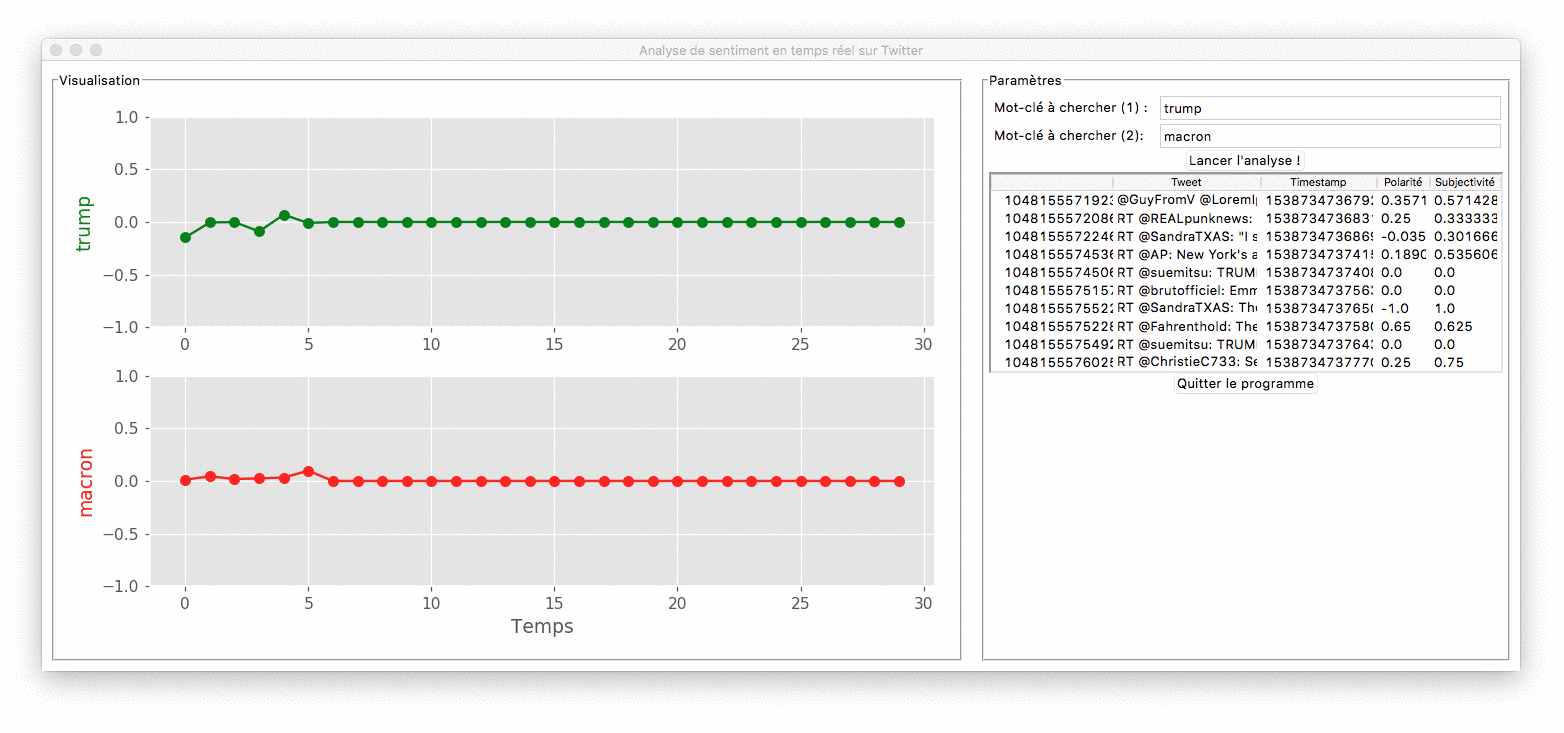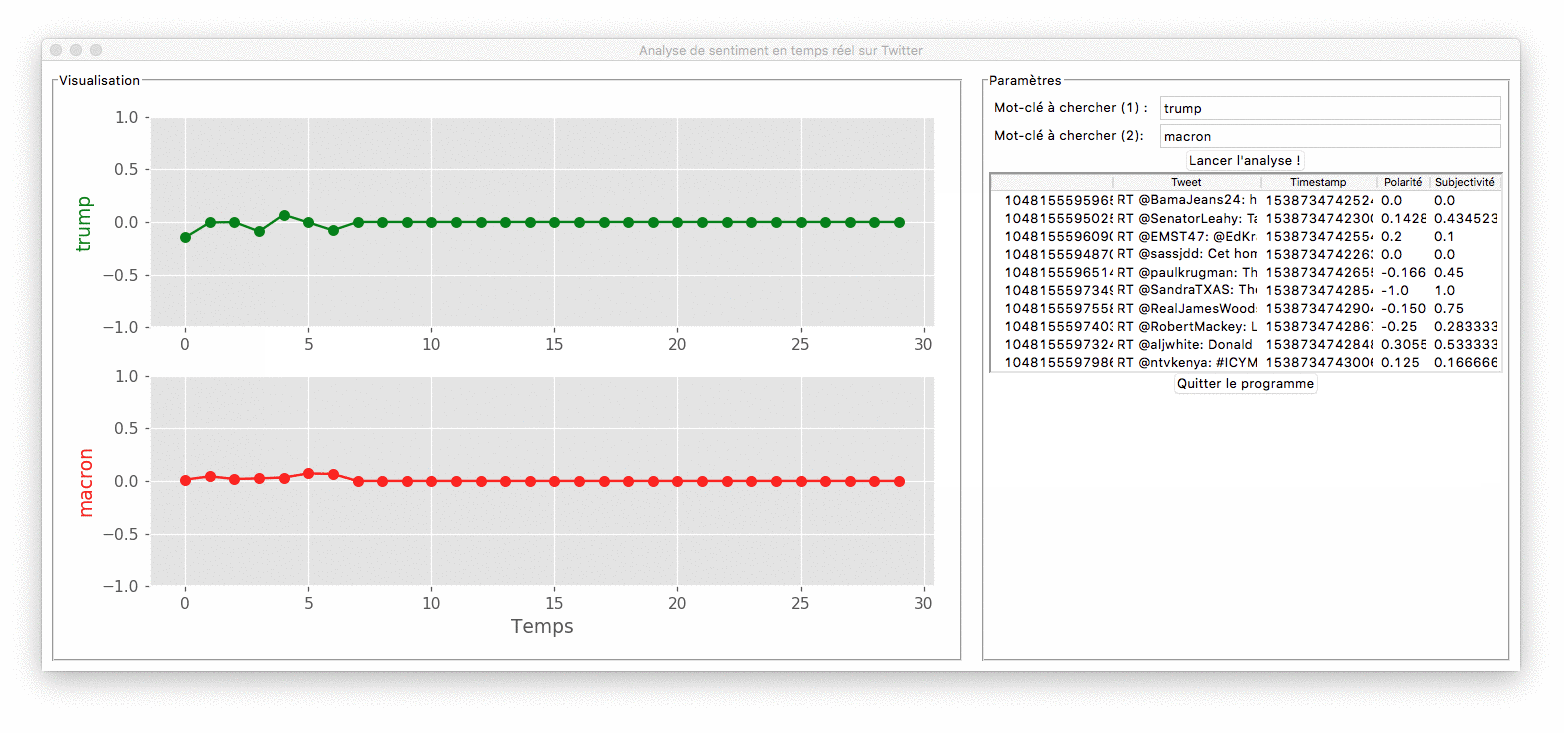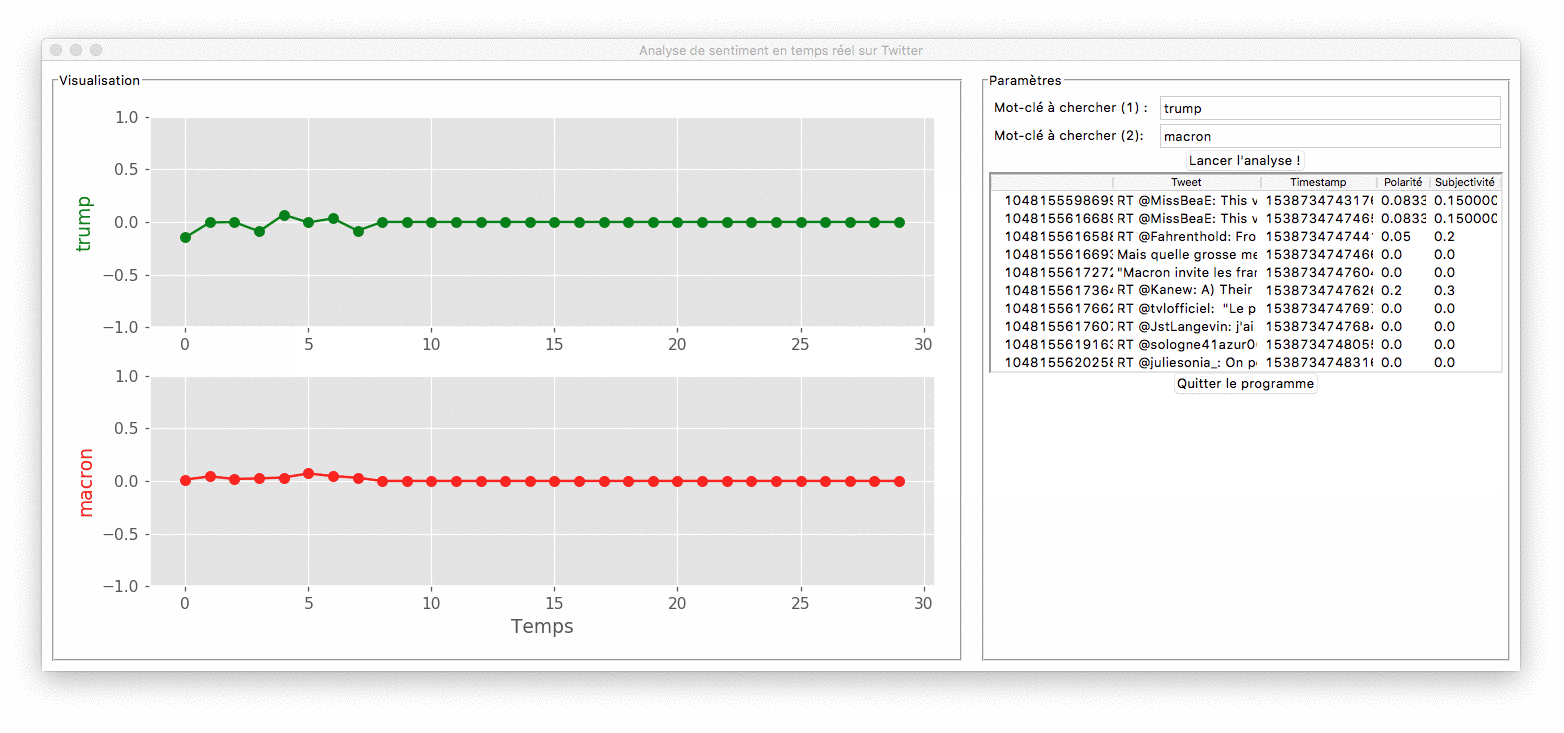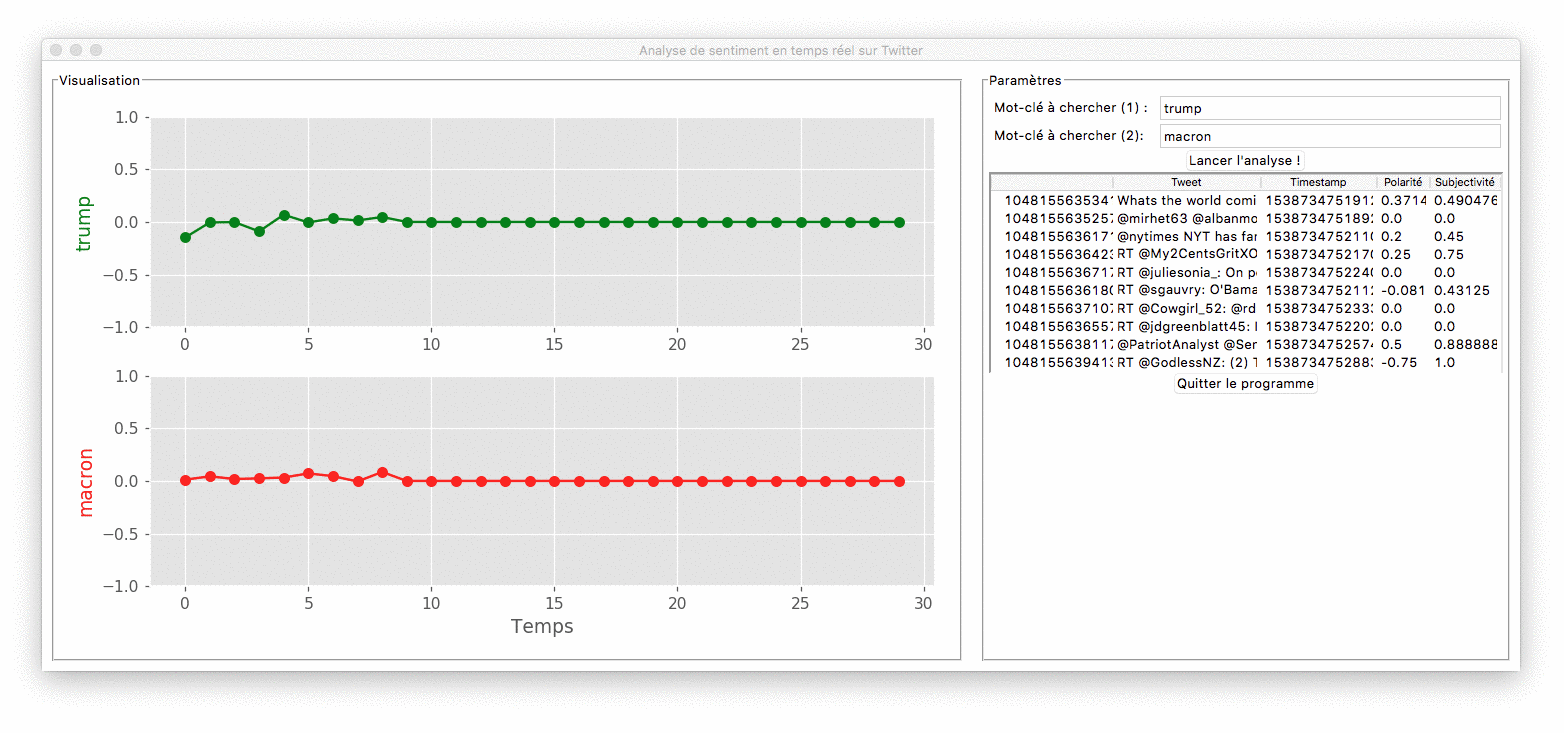
Le cahier des charges
Avant de nous lancer tête baissée dans le développement de l’application, listons un petit cahier des charges :
- le programme se présentera sous forme d’interface graphique (GUI) avec notamment 2 widgets d’entrée (text input) pour que l’on puisse analyser le trafic de 2 mots-clés simultanément (c’est cet aspect-là qui va poser problème, la concurrence en Python étant difficile à exploiter)
- le programme devra être capable de se connecter à Twitter afin de réceptionner en temps réel (streaming) les tweets liés aux 2 mots-clés saisis, et stocker les tweets dans une structure de donnée adéquate
- le programme devra analyser les tweets stockés, c’est-à-dire calculer un score de neutralité et de subjectivité. Nous n’allons pas implémenter cette fonction nous-même mais utiliser le module TextBlob, qui utilise un algorithme Vador pour estimer le résultat.
- et il devra afficher ce score en fonction du temps dans un graphique. Nous créerons 2 graphiques, un pour chaque mot-clé. L’unité et la fenêtre de temps utilisées pour créer les graphiques seront modifiables grâce à 2 paramètres dans notre code.
- le programme étant relativement simple, nous arriverons à faire rentrer tout le code dans un seul fichier Python. N’oubliez pas qu’il est impératif pour un projet de plus grande envergure de bien séparer son programme en plusieurs fichiers/modules, afin de rendre le code réutilisable et plus facilement modifiable.
Note : Le module TextBlob que nous allons utiliser pour l’analyse de sentiment est basé sur NLTK, une bibliothèque Python de NLP très réputée dans le milieu scientifique et académique.
En-tête
Pour la suite du projet, je vous fournis les premières lignes d’en-tête que vous n’avez qu’à copier-coller. Nous nous contentons de spécifier l’encodage, d’importer les modules adéquats et de conseiller la version Python à utiliser.
#!/usr/bin/python3 # -*- coding: utf-8 -*- # Version recommandée : Python 3.6 # Python 3.7 est incompatible à ce jour avec Tweepy import tkinter as tk from tkinter import ttk from tkinter import messagebox import tweepy from matplotlib.figure import Figure from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg from matplotlib.animation import FuncAnimation import matplotlib.animation as animation from matplotlib import style import threading import time import os from textblob import TextBlob import pandas as pd import numpy as np
Se connecter à Twitter
Puisqu’il nous faut bien démarrer quelque part, commençons par nous connecter à Twitter. Pour cela, nous allons créer une classe qui hérite de tweepy.StreamListener. Cet héritage nous permet de redéfinir la fonction on_status qui est appelée pour chaque nouveau tweet reçu.
def convertir_str(chaine):
""" Enleve les caractères interdits comme les emojis (UTF-16) """
char_list = [chaine[j]
for j in range(len(chaine)) if ord(chaine[j]) in range(65536)]
resultat = ''
for j in char_list:
resultat = resultat + j
return resultat
class TwitterListener(tweepy.StreamListener):
def on_status(self, status):
texte_tweet = convertir_str(status.text)
print(texte_tweet)
Nous définissons ensuite une fonction qui instancie la classe TwitterListener dans un nouveau thread. Un Thread permet d’exécuter en parallèle une série d’instructions. C’est ce qui nous permettra de recevoir les tweets tout en affichant une interface graphique réactive.
def start_listening_twitter():
myStreamListener = TwitterListener()
myStream = tweepy.Stream(auth=api.auth, listener=myStreamListener)
myStream.filter(track=["bitcoin", "python"])
listening_twitter_thread = threading.Thread(
target=start_listening_twitter)
listening_twitter_thread.start()
listening_twitter_thread.join()
Pour l’instant les mots-clés à tracker (« bitcoin » et « python ») sont écrits en dur dans le code mais nous allons changer ça quand nous passerons à l’interface graphique.
La fonction join() attend que le Thread se termine pour passer à l’instruction suivante. Problème : nous ne lui disons pas quand s’arrêter. Pour arrêter l’appel à la fonction filter(), il suffit de retourner False dans la méthode on_status. Nous utiliserons cette fonctionnalité quand nous créerons l’interface graphique (cela nous permettra d’arrêter le thread qui écoute les tweets pour le relancer quelques secondes plus tard avec de nouveaux mots-clés saisis par l’utilisateur).
Calculer le score de polarité et de subjectivité
Nous allons tout d’abord créer un Dataframe (grâce au module Pandas) qui va stocker plusieurs choses. Pour respecter le cahier des charges, nous devons ainsi sauvegarder :
- l’heure à laquelle le tweet a été émis. Nous enregistrerons ainsi un timestamp UNIX en millisecondes ; il s’agit du nombre de millisecondes écoulées depuis le 1er janvier 1970. Cela nous permettra plus tard de resampler les tweets proches dans le temps pour faire notre graphique.
- le texte du tweet. En effet, nous afficherons le contenu du tweet dans une vue de notre interface graphique pour surveiller le bon fonctionnement du programme.
- le score de polarité : calculé grâce à TextBlob, il indique si le sentiment est négatif ou plutôt positif. Il est compris entre une échelle de -1 (très négatif) à 1 (très positif), 0 signifiant un avis neutre.
- le score de subjectivité : lui aussi calculé grâce à TextBlob, il indique la subjectivité du texte, c’est-à-dire si le sentiment exprimé est personnel ou est plutôt factuel. Son échelle va de -1 (subjectif) à 1 (objectif). Nous n’allons pas vraiment utiliser cette métrique.
En Python, cela peut être réalisé en déclarant une variable globale :
dataframe_tweets = pd.DataFrame(columns=['timestamp_ms', 'keyword_id',
'polarity', 'subjectivity'])
Puis en modifiant notre fonction on_status() appelée à la réception de chaque tweet :
tweet_analysis = TextBlob(texte_tweet)
# Ajout à la liste des tweets
liste_tweets.insert("", "end", text=status.id, values=(
str(texte_tweet),
str(status.timestamp_ms),
tweet_analysis.polarity,
tweet_analysis.subjectivity))
dataframe_tweets = dataframe_tweets.append({
"timestamp_ms": int(status.timestamp_ms),
"keyword_id": is_first_keyword,
"polarity": tweet_analysis.polarity,
"subjectivity": tweet_analysis.subjectivity
}, ignore_index=True)
Créer une interface graphique
L’interface graphique sera réalisée avec le module TKinter. TKinter permet de créer facilement des interfaces graphiques mais ne dispose pas de beaucoup de widgets ou d’options de personnalisation. Cela sera néanmoins suffisant pour notre projet mais sachez qu’il existe PySide2, le binding officiel de Qt pour Python. Il existe d’autres bindings de Qt et également GTK.
Pour créer une interface graphique, il suffit de créer un objet Tk qui sera la fenêtre principale de notre programme. Nous ajouterons à cet objet, les widgets désirés par appel successif aux fonctions pack() ou grid(), qui nous permettent de positionner les widgets dans la fenêtre.
Le code qui suit permet de créer entièrement l’interface graphique du programme
app = tk.Tk()
app.wm_title("Analyse de sentiment en temps réel sur Twitter")
style.use("ggplot")
fig = Figure(figsize=(8, 5), dpi=112)
ax1 = fig.add_subplot(211)
ax2 = fig.add_subplot(212, sharex=ax1)
ax2.set_xlabel('Temps')
ax1.set_ylabel('Keyword 1', color='g')
ax2.set_ylabel('Leyword 2', color='r')
fig.set_tight_layout(True)
# Groupbox de visualisation
groupbox_visualisation = tk.LabelFrame(
master=app, text="Visualisation", padx=5, pady=5)
groupbox_visualisation.pack(fill='both',
expand=True, padx=10, pady=10, side="left")
graph = FigureCanvasTkAgg(fig, master=groupbox_visualisation)
canvas = graph.get_tk_widget()
canvas.pack(side="top", fill='both', expand=True)
# Groupbox de paramètres
groupbox_param = tk.LabelFrame(
master=app, text="Paramètres", padx=5, pady=5)
groupbox_param.pack(fill='both',
expand=True, padx=10, pady=10, side="right")
groupbox_param.grid_columnconfigure(1, weight=1)
# Premier mot clé
label_widget_1 = tk.Label(groupbox_param, text="Mot-clé à chercher (1) : ")
label_widget_1.grid(row=0, sticky="w")
premier_keyword = tk.Entry(master=groupbox_param)
premier_keyword.grid(row=0, column=1, sticky="ew")
premier_keyword.insert(0, "macron")
# Deuxième mot clé
label_widget_2 = tk.Label(
groupbox_param, text="Mot-clé à chercher (2): ")
label_widget_2.grid(row=1, sticky="w")
deuxieme_keyword = tk.Entry(master=groupbox_param)
deuxieme_keyword.grid(row=1, column=1, sticky="ew")
deuxieme_keyword.insert(0, "trump")
app.protocol("WM_DELETE_WINDOW", fermer_programme)
# Boucle d'événement principal, lance la fenetre, gere les interactions
app.mainloop()
La fonction lancer_analyse() permet d’arrêter le thread qui écoute les tweets et de le relancer avec les mots-clés insérés par l’utilisateur au travers de l’interface graphique :
def lancer_analyse():
""" Fonction appelée lors du clic sur le bouton d'analyse """
global should_stop, listening_twitter_thread
should_stop = True # permet d'arreter l'analyse des anciens mots-clés
listening_twitter_thread.join() # dès que l'ancien thread se termine
# relance une analyse avec les nouveaux mots-clés
listening_twitter_thread = threading.Thread(
target=start_listening_twitter)
listening_twitter_thread.start()
Nous définissons ensuite la fonction fermer_programme, appelée lorsque l’on souhaite… quitter le programme :
def fermer_programme():
global should_stop
if tk.messagebox.askokcancel("Quitter", "Voulez-vous vraiment quitter ?"):
# Normalement on doit cloturer plus proprement le thread principal
# et le thread secondaire. 0 pour indiquer au système que tout a fonctionné.
os._exit(0)
Créer le graphique
Matplotlib est incontournable en Python lorsque l’on souhaite faire de la visualisation de données. Il permet de créer des graphiques de toute sorte et ses options sont nombreuses. Pour notre projet, nous n’utiliserons que quelques fonctions simples d’utilisation.
Ici nous créons un graphique contenant 2 sous-graphiques en ligne, le premier ayant la couleur vert (‘g’) et le deuxième en rouge (‘r’) :
style.use("ggplot")
fig = Figure(figsize=(8, 5), dpi=112)
ax1 = fig.add_subplot(211)
ax2 = fig.add_subplot(212, sharex=ax1)
ax2.set_xlabel('Temps')
ax1.set_ylabel('Keyword 1', color='g')
ax2.set_ylabel('Leyword 2', color='r')
fig.set_tight_layout(True)
Nous définissons ensuite une fonction qui indique comment retracer le graphique :
def update_graph(dt):
x, y1, y2 = get_back_values()
ax1.clear()
ax2.clear()
ax1.set_ylim(-1, 1, auto=False)
ax2.set_ylim(-1, 1, auto=False)
ax2.set_xlabel('Temps')
ax1.set_ylabel(premier_keyword.get(), color='g')
ax2.set_ylabel(deuxieme_keyword.get(), color='r')
ax1.plot(x, y1, 'g-o')
ax2.plot(x, y2, 'r-o')
Puis de dire à matplotlib que nous souhaitons retracer le graphique avec cette fonction toutes les 500ms par exemple :
# Callback de rafraichissement du graphique toutes les 500ms ani = animation.FuncAnimation(fig, update_graph, interval=500)
Code final
Pour ceux qui veulent le code complet du programme, le voici :
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# Version recommandée : Python 3.6
# Python 3.7 est incompatible à ce jour avec Tweepy
import tkinter as tk
from tkinter import ttk
from tkinter import messagebox
import tweepy
from matplotlib.figure import Figure
from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg
from matplotlib.animation import FuncAnimation
import matplotlib.animation as animation
from matplotlib import style
import threading
import time
import os
from textblob import TextBlob
import pandas as pd
import numpy as np
# identifiants à récupérer dans les paramètres twitter de votre compte
consumer_key = "votre consumer key ici"
consumer_secret = "votre consumer secret ici"
access_token = "2180354412-3Vv1O503RxtL7OyNIbSo47Iu1UUeFAseTgGnDlO"
access_token_secret = "c5DwX38AR62xtGR9gMb4MXaF4wV6PflUjqsGBDmHYymDU"
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
xar = list()
yar = list()
should_stop = False
unite_temps = 5 # 5 secondes pour l'agrégation des données
nbr_points = 30 # 30 points sur le graphique
dataframe_tweets = pd.DataFrame(columns=['timestamp_ms', 'keyword_id',
'polarity', 'subjectivity'])
print(dataframe_tweets)
# INTERFACE
app = tk.Tk()
app.wm_title("Analyse de sentiment en temps réel sur Twitter")
style.use("ggplot")
fig = Figure(figsize=(8, 5), dpi=112)
ax1 = fig.add_subplot(211)
ax2 = fig.add_subplot(212, sharex=ax1)
ax2.set_xlabel('Temps')
ax1.set_ylabel('Keyword 1', color='g')
ax2.set_ylabel('Leyword 2', color='r')
fig.set_tight_layout(True)
# Groupbox de visualisation
groupbox_visualisation = tk.LabelFrame(
master=app, text="Visualisation", padx=5, pady=5)
groupbox_visualisation.pack(fill='both',
expand=True, padx=10, pady=10, side="left")
graph = FigureCanvasTkAgg(fig, master=groupbox_visualisation)
canvas = graph.get_tk_widget()
canvas.pack(side="top", fill='both', expand=True)
# Groupbox de paramètres
groupbox_param = tk.LabelFrame(
master=app, text="Paramètres", padx=5, pady=5)
groupbox_param.pack(fill='both',
expand=True, padx=10, pady=10, side="right")
groupbox_param.grid_columnconfigure(1, weight=1)
# Premier mot clé
label_widget_1 = tk.Label(groupbox_param, text="Mot-clé à chercher (1) : ")
label_widget_1.grid(row=0, sticky="w")
premier_keyword = tk.Entry(master=groupbox_param)
premier_keyword.grid(row=0, column=1, sticky="ew")
premier_keyword.insert(0, "javascript")
# Deuxième mot clé
label_widget_2 = tk.Label(
groupbox_param, text="Mot-clé à chercher (2): ")
label_widget_2.grid(row=1, sticky="w")
deuxieme_keyword = tk.Entry(master=groupbox_param)
deuxieme_keyword.grid(row=1, column=1, sticky="ew")
deuxieme_keyword.insert(0, "python")
def lancer_analyse():
""" Fonction appelée lors du clic sur le bouton d'analyse """
global should_stop, listening_twitter_thread
should_stop = True # permet d'arreter l'analyse des anciens mots-clés
listening_twitter_thread.join() # dès que l'ancien thread se termine
# relance une analyse avec les nouveaux mots-clés
listening_twitter_thread = threading.Thread(
target=start_listening_twitter)
listening_twitter_thread.start()
def fermer_programme():
global should_stop
if tk.messagebox.askokcancel("Quitter", "Voulez-vous vraiment quitter ?"):
# Normalement on doit cloturer plus proprement le thread principal
# et le thread secondaire. 0 pour indiquer au système que tout a fonctionné.
os._exit(0)
app.protocol("WM_DELETE_WINDOW", fermer_programme)
# Bouton d'analyse
bouton_analyse = tk.Button(master=groupbox_param,
text="Lancer l'analyse !", command=lancer_analyse)
bouton_analyse.grid(row=2, column=0, columnspan=2)
# Liste des tweets avec scrollbar
liste_tweets = ttk.Treeview(master=groupbox_param)
liste_tweets["columns"] = ("tweet", "timestamp", "polarity", "subjectivity")
liste_tweets.column("tweet", width=220)
liste_tweets.column("timestamp", width=50)
liste_tweets.column("polarity", width=20)
liste_tweets.column("subjectivity", width=20)
liste_tweets.heading("tweet", text="Tweet")
liste_tweets.heading("timestamp", text="Timestamp")
liste_tweets.heading("polarity", text="Polarité")
liste_tweets.heading("subjectivity", text="Subjectivité")
liste_tweets.grid(row=3, column=0, columnspan=2, sticky="nsew")
# Bouton quitter
bouton_quitter = tk.Button(master=groupbox_param,
text="Quitter le programme", command=fermer_programme)
bouton_quitter.grid(row=4, column=0, columnspan=2, sticky="s")
# FONCTIONS
def get_back_values():
# On supprime les trop vielles valeurs
global dataframe_tweets
print(dataframe_tweets)
dataframe_tweets.index = pd.to_datetime(dataframe_tweets.timestamp_ms, unit="ms")
dataframe_tweets = dataframe_tweets.drop(
dataframe_tweets[dataframe_tweets.timestamp_ms.astype(int) < int(round(time.time() * 1000)) - unite_temps * nbr_points * 1000].index)
x = range(nbr_points)
try:
y1 = dataframe_tweets[dataframe_tweets.keyword_id ==
True].polarity.resample(str(unite_temps) + 'S').mean().fillna(method='backfill')
y2 = dataframe_tweets[dataframe_tweets.keyword_id ==
False].polarity.resample(str(unite_temps) + 'S').mean().fillna(method='backfill')
except:
return get_back_values()
# Si la longueur du tableau est insuffisante (vrai à l'initialisation), on remplit avec des 0
y1 = np.pad(y1, max(nbr_points - len(y1), 0), 'constant', constant_values=(0))[-nbr_points:]
y2 = np.pad(y2, max(nbr_points - len(y2), 0), 'constant', constant_values=(0))[-nbr_points:]
return x, y1, y2
def update_graph(dt):
x, y1, y2 = get_back_values()
ax1.clear()
ax2.clear()
ax1.set_ylim(-1, 1, auto=False)
ax2.set_ylim(-1, 1, auto=False)
ax2.set_xlabel('Temps')
ax1.set_ylabel(premier_keyword.get(), color='g')
ax2.set_ylabel(deuxieme_keyword.get(), color='r')
ax1.plot(x, y1, 'g-o')
ax2.plot(x, y2, 'r-o')
def convertir_str(chaine):
char_list = [chaine[j]
for j in range(len(chaine)) if ord(chaine[j]) in range(65536)]
resultat = ''
for j in char_list:
resultat = resultat + j
return resultat
class TwitterListener(tweepy.StreamListener):
def on_status(self, status):
global should_stop, dataframe_tweets
if should_stop:
should_stop = False
return False
if len(xar) == 0:
xar.append(0)
else:
xar.append(xar[-1] + 1)
yar.append(int(status.user.id_str))
texte_tweet = convertir_str(status.text)
tweet_analysis = TextBlob(texte_tweet)
# Ajout à la liste des tweets
liste_tweets.insert("", "end", text=status.id, values=(
str(texte_tweet),
str(status.timestamp_ms),
tweet_analysis.polarity,
tweet_analysis.subjectivity))
is_first_keyword = premier_keyword.get().casefold() in map(str.casefold, texte_tweet.split())
dataframe_tweets = dataframe_tweets.append({
"timestamp_ms": int(status.timestamp_ms),
"keyword_id": is_first_keyword,
"polarity": tweet_analysis.polarity,
"subjectivity": tweet_analysis.subjectivity
}, ignore_index=True)
# 50 derniers tweets affichés
if len(liste_tweets.get_children()) > 50:
premier_item = liste_tweets.get_children()[0]
liste_tweets.delete(premier_item)
# On défile vers le dernier élément
liste_tweets.see(liste_tweets.get_children()[-1])
def start_listening_twitter():
myStreamListener = TwitterListener()
myStream = tweepy.Stream(auth=api.auth, listener=myStreamListener)
myStream.filter(track=[premier_keyword.get(), deuxieme_keyword.get()])
listening_twitter_thread = threading.Thread(
target=start_listening_twitter)
listening_twitter_thread.start()
# Callback de rafraichissement du graphique toutes les 500ms
ani = animation.FuncAnimation(fig, update_graph, interval=500)
# Boucle d'événement principal, lance la fenetre, gere les interactions
app.mainloop()
Conclusion
Le programme a été implémenté en moins de 250 lignes, avec de nombreux commentaires. Pour ceux qui sont intéressés, voici quelques pistes d’amélioration :
- généraliser le programme non pas à 2 mais n mots-clés. Il vous faut repenser un peu l’interface graphique mais cela ne devrait pas vous poser problème.
- permettre d’enregistrer dans un fichier CSV les données du dataframe (très facile à faire, je vous laisse chercher la fonction)
- utiliser non pas TextBlob mais son propre algorithme d’analyse de sentiments ! Renseignez-vous sur l’algorithme Vador, constituez votre propre lexique et rendez le programme compatible avec les emojis 🙂
- une meilleure gestion des erreurs : des rares cas peuvent faire planter le programme, à vous de gérer les exceptions proprement
- éliminer les RT (re tweets) de l’analyse : si vous regardez la démonstration, plusieurs tweets commencent par « RT ». Il faut les éliminer ou les pondérer plus faiblement qu’un tweet principal.
J’espère que cet article vous aura plu, n’hésitez pas à laisser un commentaire si vous avez besoin d’aide.